2015년 4월 13일 월요일
[Flask] All about critics
Github : https://github.com/carpedm20/all-about-critics
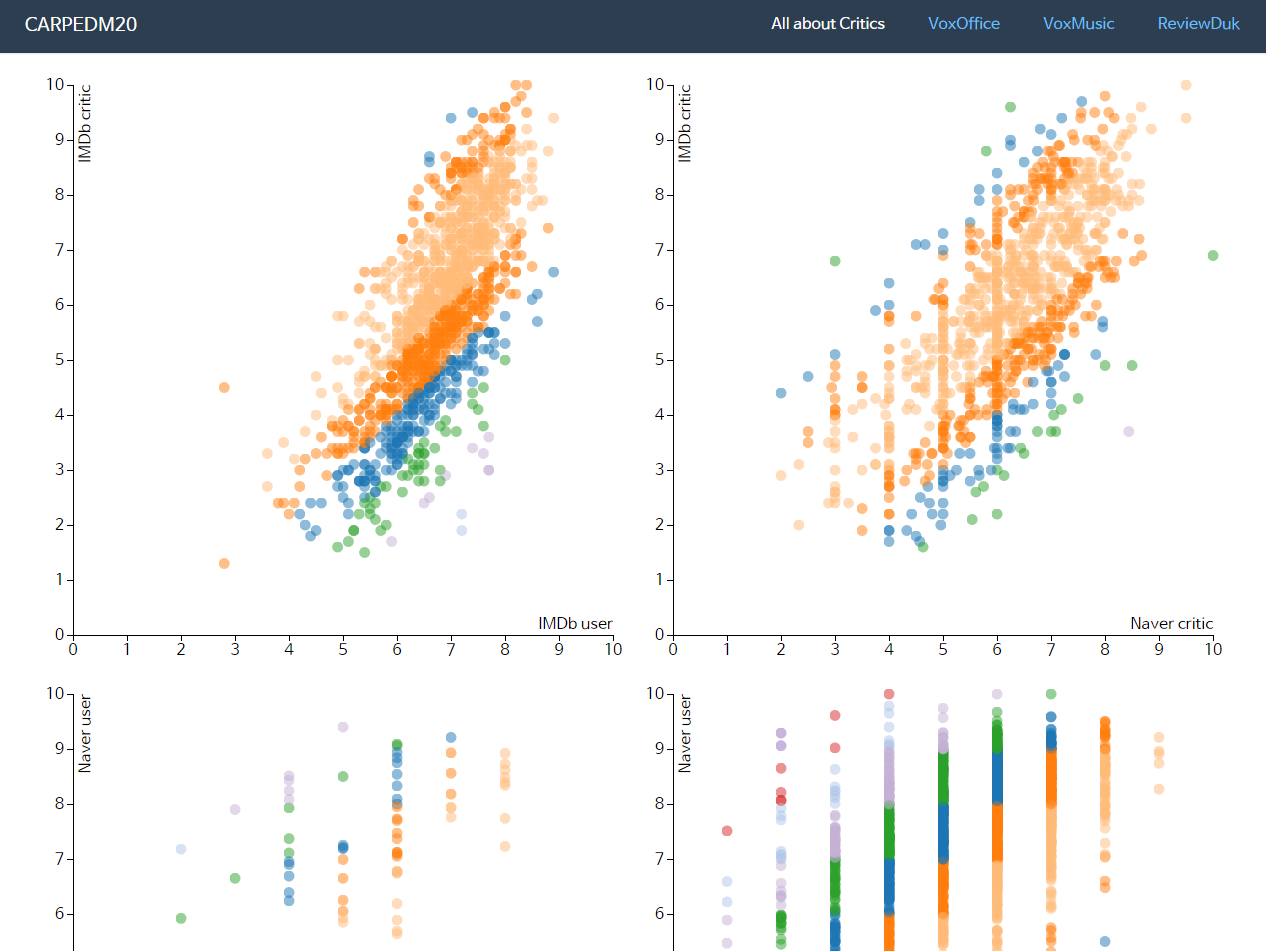
A Data Visualization of Korean movie critics. link
Why?
Tons of new movies are released every year and the accumulated number of film reviews is increasing. When we are going to choose a movie to watch, we can judge them by diverse preferences such as genre, director or actors.
There mgiht be no doubt that review and star ratings are two of the most popular qualites and this can be proved by looking at information page of NAVER movie that star ratings from real audience, critic and user are located right bellow the title of a movie.
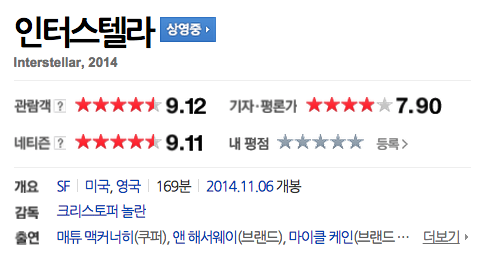
In addition, one of the well-knwon movie recommendation service, Watcha, uses star rating for its core recommendation system.

Anyone can post reviews or make star ratings and we usually classify them based on who made it, an ordinary user, or a critic. By the definition on Wikipedia, a critic is a person who is professional at an area and his or her publish an opinion and assessments of various forms of creative work such as movie. Critical judgments, whether derived from critical thinking or not, may be positive, negative, or balanced, weighing a combination of factors.
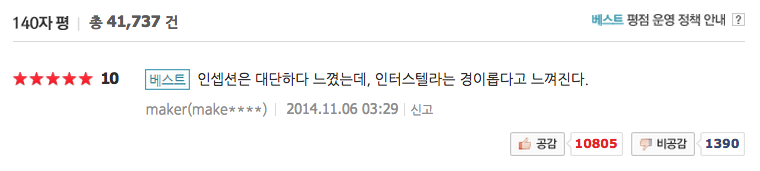

Recently, however, lots of questions are made by lots of movie fans that "Are reviews of critics really considerable or not?"

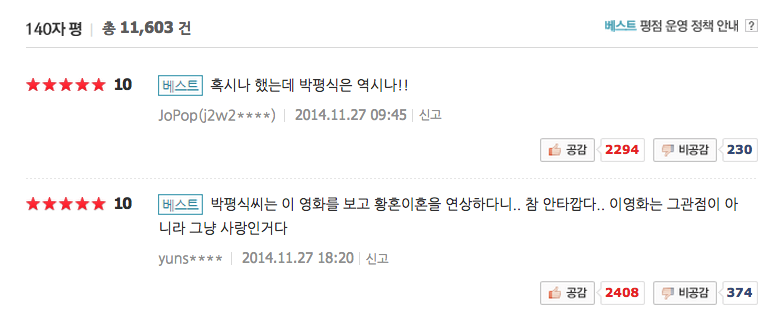
This is where I started this project. As a movie fan, I statistically compared the patterns of star ratings from ordinary users and critics. To generalized the analysis, I comapred critics of Korean withMetacritic and Rotten Tomatoes. The result can be conceived as a proof whether skepticism about the quality of critics is right or not.
Now, enjoy yourself :)
Screenshot
Acknowledgement
There is no negative or positive opinion on any specific critics. Data is just a refinement of numbers, nothing else.
Copyright
Copyright  2015 Kim Tae Hoon.
2015 Kim Tae Hoon.
The MIT License (MIT)
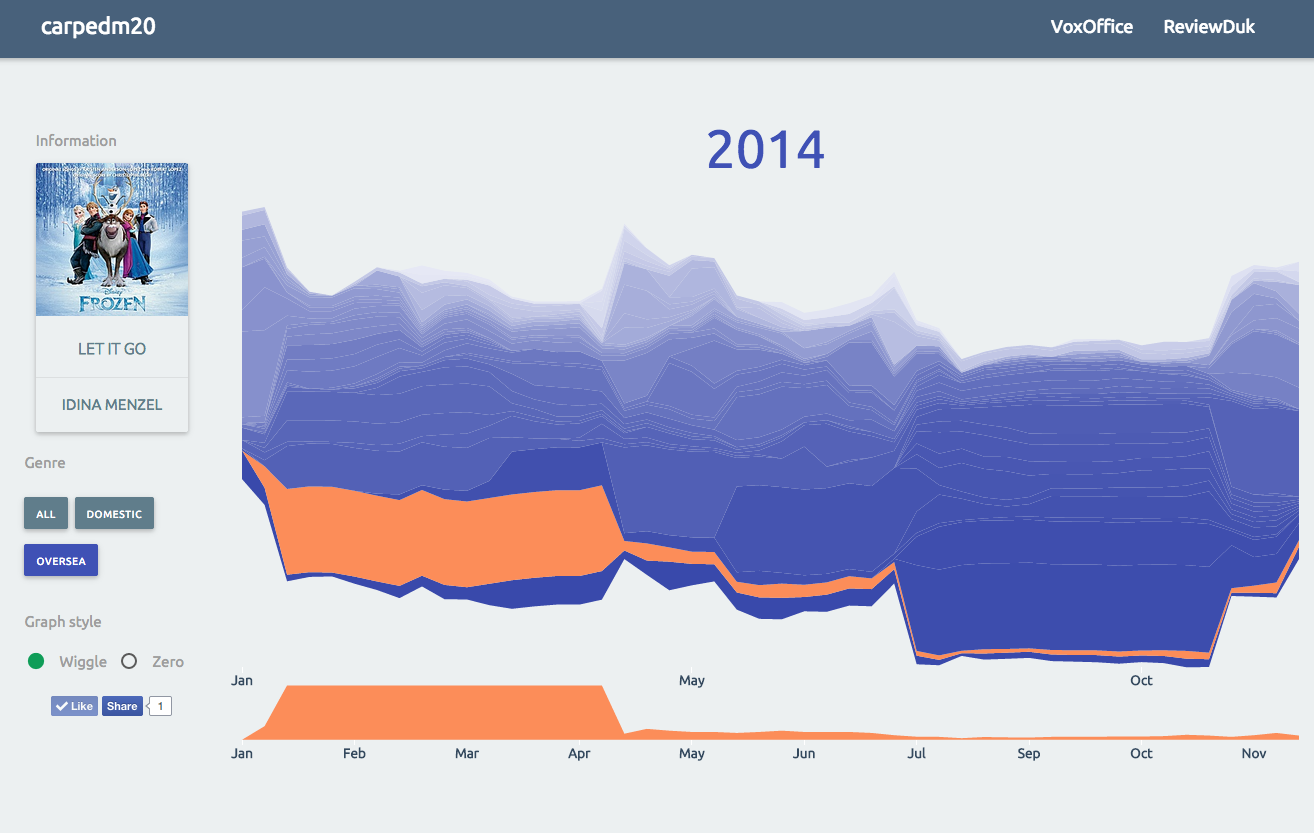
[Flask] VoxOffice
Github : https://github.com/carpedm20/voxoffice
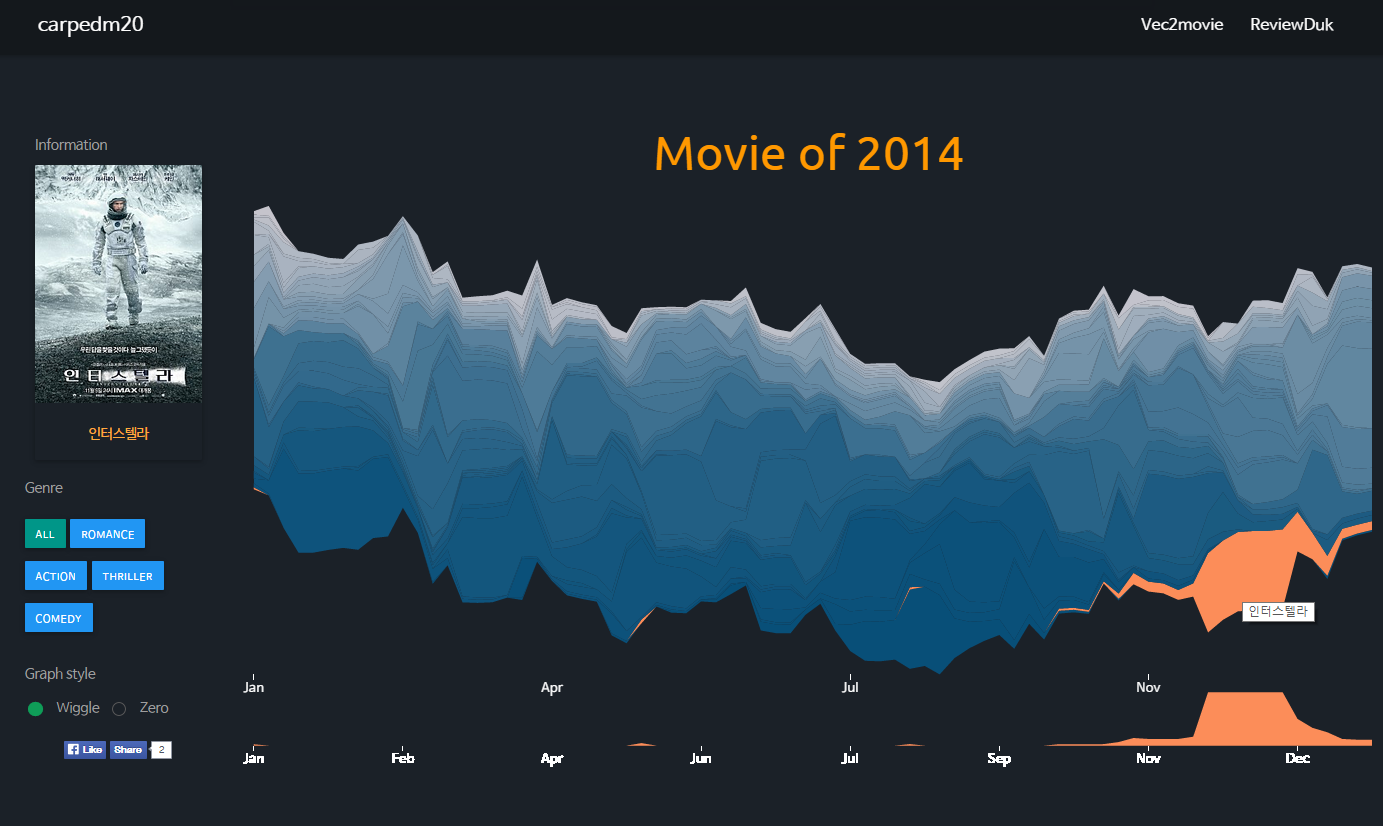
A Data Visualization of Box office history. link
Screenshot


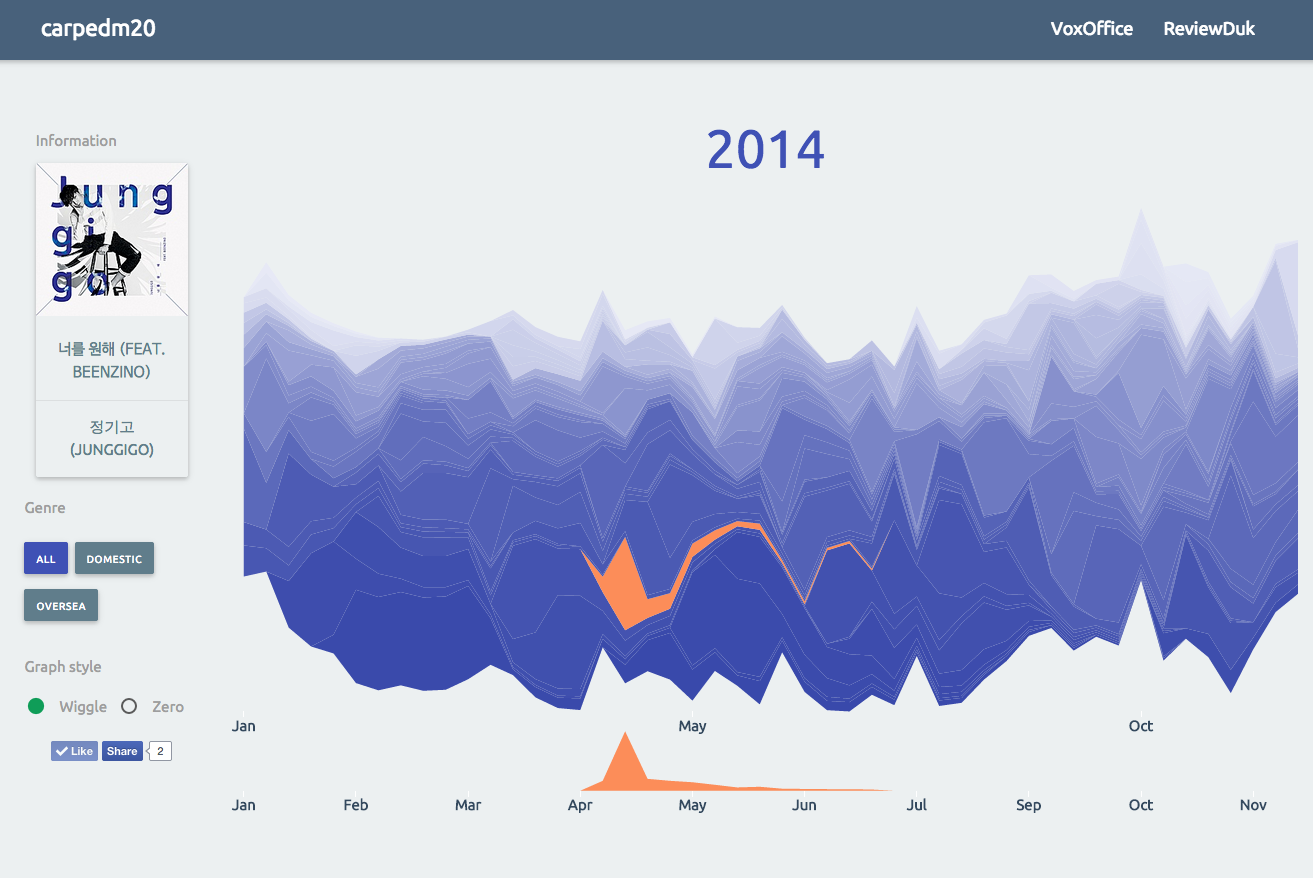
VoxMusic
A Data Visualization of Music chart history. link
Copyright
Copyright 2015 Kim Tae Hoon
The MIT License (MIT)
[Python] 컴공아 떠나자
Github : https://github.com/carpedm20/comgong-abroad
컴공아 떠나자 (a.k.a. Comgong Abroad) is a robot that uploads newest internship and recruit announcements of overseas corporation to Facebook automatically.
Facebook page : link
Copyright
Copyright 2015 Kim Tae Hoon
The MIT License (MIT)
Screenshots
* 2015.04.17 *

* 2015.04.13 *
* 2015.04.13 *
2014년 8월 18일 월요일
[Python] emoji
Emoji
Emoji is a simple Python module.
Installation
To install ndrive, simply:
$ pip install emoji
Example
from emoji import emojize
print emojize("Python is :thumbsup:")
print emojize("Do you want some :beer: ?")
Demo

Link
Author
Taehoon Kim / @carpedm20
2014년 8월 3일 일요일
[Python] korail2
Korail2
Korail (www.letskorail.com) wrapper for Python.
korail is not working anymore becuase of a huge change in Korail API.
Installing
To install korail2, simply:
$ pip install korail2
Or, you can use:
$ easy_install korail2
Or, you can also install manually:
$ git clone git://github.com/carpedm20/korail2.git
$ cd korail2
$ python setup.py install
Using
1. Login
First, you need to create a Korail object.
>>> from korail2 import Korail
>>> korail = Korail("12345678", YOUR_PASSWORD) # with membership number
>>> korail = Korail("carpedm20@gmail.com", YOUR_PASSWORD) # with email
>>> korail = Korail("010-9964-xxxx", YOUR_PASSWORD) # with phone number
2. Search train
You can search train schedules
search_train method. search_train method takes these arguments:- dep : A departure station in Korean ex) '서울'
- arr : A arrival station in Korean ex) '부산'
- date : (optional) A departure date in
yyyyMMddformat - time : (optional) A departure time in
hhmmssformat - train_type: (optional) A type of train
- 00: KTX
- 01: 새마을호
- 02: 무궁화호
- 03: 통근열차
- 04: 누리로
- 05: 전체 (기본값)
- 06: 공학직통
- 07: KTX-산천
- 08: ITX-새마을
- 09: ITX-청춘
Below is a sample code of
search_train:>>> dep = '서울'
>>> arr = '동대구'
>>> date = '20140815'
>>> time = '144000'
>>> trains = korail.search_train(dep, arr, date, time)
[[KTX] 8월 3일, 서울~부산(11:00~13:42) [특실:1][일반실:1] 예약가능,
[ITX-새마을] 8월 3일, 서울~부산(11:04~16:00) [일반실:1] 예약가능,
[무궁화호] 8월 3일, 서울~부산(11:08~16:54) [일반실:0] 입석 역발매중,
[ITX-새마을] 8월 3일, 서울~부산(11:50~16:50) [일반실:0] 입석 역발매중,
[KTX] 8월 3일, 서울~부산(12:00~14:43) [특실:1][일반실:1] 예약가능,
[KTX] 8월 3일, 서울~부산(12:30~15:13) [특실:1][일반실:1] 예약가능,
[KTX] 8월 3일, 서울~부산(12:40~15:45) [특실:1][일반실:1] 예약가능,
[KTX] 8월 3일, 서울~부산(12:55~15:26) [특실:1][일반실:1] 예약가능,
[KTX] 8월 3일, 서울~부산(13:00~15:37) [특실:1][일반실:1] 예약가능,
[KTX] 8월 3일, 서울~부산(13:10~15:58) [특실:1][일반실:1] 예약가능]
3. Make a reservation
You can get your tickes with
tickets method.>>> trains = korail.search_train(dep, arr, date, time)
>>> seat = korail.reserve(trains[0])
정상처리되었습니다
동일시간대 예약발매내역이 있습니다.
>>> seat
[KTX] 8월 3일, 서울~부산(11:00~:) 16호 6A
4. Get tickets
You can get your tickes with
tickets method.>>> tickets = k.tickets()
정상발매처리,정상발권처리
>>> tickets
[[KTX] 8월 10일, 동대구~울산(09:26~09:54) => 5호 4A, 13900원]
How do I get the Korail API
Todo
- Distinguish adult and child
- Make an option to select special seat or general seat when reserving
- Make an option to reserve multiple seats at a time
- Implement payment API
License
Source codes are distributed under BSD license.
Author
Taehoon Kim / @carpedm20
2014년 8월 2일 토요일
[Django] UNIST Auction
UNIST Auction
Auction for UNIST
Copyright
Copyright 2014 Kim Tae Hoon.
The MIT License (MIT)


2014년 6월 11일 수요일


2014년 6월 5일 목요일
[Django] MovieTag

Find a movie to watch with any tags you want!
Tags are automatically generated with morpheme analysis of big data.
Percentage of positive and negative reviews will be given through deep learning.
Documentation
The documentation is available at ???
Development History
- Plan to make a web service which can search any movie with tags
- saw a new feature Game tag from steam
- saw a restaurant recommendation service "Dining code" using big data (reviews from blogs)
- want to find a movie not with a category like Romance but with a tag like first love,farewell etc.
- Movie review parsing
- save data as json
- Morpheme analysis
- first, used lucene-korean-analyzer
- have a weakness that cannot distinguish predicate and uninflected word and hard to get word frequencies from reviews
- next, used mecab-ko and mecab-ko-dic
- can get details from review like predicate and uninflected word information D4. Build a DB
- to connect with django, write a python code that import json data to SQLite
- but too slow file-io and cannot write a multi-thread code because of file lock (estimated time to import all data was 6 days)
- change DB to MySQL
- faster file-io and possible to write a multi-thread code (1~2 days)
- but sorting a movie with a specific tag was too slow
- plan to use Apache Cassandra, but found that it has slower read than write from google.
- data was json, so used MongoDB
- data import was finished only in a few seconds with
mongoimport(Assert failure on mongorestore (b.empty()) error occured because of huge json file. so split the data into small files) - DB querying speed was fater than MySQL (hooray~)
- Conclusion : Text indexing of MongoDB make faster speed than raw query of MySQL +Django
- Build a web
- used Django webframework
- Back-end : used Django, South, endless-pagination etc.
- Front-end : used jQuery, Bootstrap, Bootstrap-twipsy, D3, Flat-UI, jQuery-Masonry,imagesloaded etc.
- complete tag search feature.
- developing infinite scroll...
- Positive & Negative review
- with review data and using Logistic regression and Deep learning, plan to distinguish reviews into positive and negative review.
- first, make an adjective and noun list by using morpheme analysis.
- star point of review and movie will be used as a label in machine learning
Developement Histroy (Korean)
- 영화를 태그로 검색하는 서비스를 만들기로 계획
- steam의 게임 태그 라는 새로운 기능을 보게됨
- 빅데이터(블로그 글)를 이용해 음식점을 추천해 주는 다이닝 코드 를 보게됨
- 로멘스처럼 거대한 카테고라기 아닌 첫사랑, 이별 과 같은 keyword로 영화를 찾고 싶음
- 영화 리뷰 파싱
- json 파일로 저장
- json 에서 tag를 {"text": "첫사랑", "freq": 1} 로 저장했으나, 쿼리 낭비를 막기 위해 {"첫사랑": 1} 로 구조 변환
- 형태소 분석
- 처음에는 lucene-korean-analyzer를 사용
- 용언, 체언을 구분 못하고, 초기 버전에는 단어의 frequency를 알 방법이 없는 단점이 있음
- 다음으로 사용한 opensource는 mecab-ko 와 mecab-ko-dic
- 용언, 체언을 세세하게 분류한 결과가 나오는 등의 장점
- DB 구축
- 처음에는 django 프로젝트와 연동을 위해 python 코드로 SQLite 에 집어 넣음
- DB에 import 하는 속도(file-io)가 너무 느림 & file-io에 lock이 걸려 멀티쓰레드를만들 수 없음 (6일 정도 소요 될 거라 예상)
- MySQL 로 DB 변경
- 넣는 속도가 sqlite 보다 월등히 빠르며, 멀티쓰레드로 돌려도 lock 처리를 MySQL이 알아서 해주는 장점 (1~2일 소요)
- 하지만 특정 tag에 대한 영화들을 tag의 frequency로 정렬하는 속도가 느림.
- Apache Cassandra 를 사용하려 했으나 짧은 구글링으로 write보다 read가 느리다는 글을 보게됨. read가 월등히 많을것이기 때문에 탈락
- 파싱 결과가 json이라는 것에 착안해 MongoDB를 사용
mongoimport를 이용해 몇 초만에 db에 들어감 (json파일이 너무 커서 Assert failure on mongorestore (b.empty()) 오류 발생. 그래서 작게 잘라 넣었음)- DB querying 속도가 월등히 빨라짐 (만세!)
- 결론 : MongoDB의 Text indexing 기능 때문에 raw query가 MySQL + Django ORM 보다 훨씬 빠른것으로 보인다
- Web 구축
- Django webframework 사용 (이번 기회에 MEAN stack을 공부하려고 했으나... 빠른 개발을 위해 포기)
- Back-end : Django, South, endless-pagination 등 사용
- Front-end : jQuery, Bootstrap, Bootstrap-twipsy, D3, Flat-UI, jQuery-Masonry,imagesloaded 등 사용
- 태그 검색 기능 완성
- infinite scroll 기능 개발 중...
- 긍정 부정 리뷰
- 파싱한 리뷰 데이터를 이용해 리뷰의 긍정, 부정을 먼저 단일 형용사, 명사와 자주 같이 등장하는 형용사, 명사 pair들을 이용해 Logistic regression 을 이용해 본 후에 Deep learning을 이용해 분석할 계획
- 먼저 리뷰를 형태소 분석을 통해서 명사, 형용사 리스트를 만듦
- 리뷰에 어떤 형용사와 명사가 사용되었는지를 바탕으로 learning 시작
- learning시 label은 리뷰의 별점 및 영화의 평균 별점이 사용될 예정
Screenshot
* 2014.06.04 *

* 2014.06.07 *



피드 구독하기:
글 (Atom)